· Tutorial · 15 min read
Logstash, ElasticSearch, Kibana - S01E02 - Analyse orientée business de vos logs applicatifs
Nous allons voir comment mettre à profit nos logs applicatifs afin de faire de l’analyse orientée "business" grâce à Logstash, ElasticSearch et Kibana.
Les logs d’une application sont utilisés le plus souvent afin d’analyser un incident en production.
Ces lignes parfois trop complexes, même pour un développeur, sont générées par Go voir Tera toutes les heures, suivant votre infrastructure.
Elles sont trop souvent sous-exploitées au regard du nombre d’informations précieuses disponibles.

Nous allons voir comment mettre à profit nos logs applicatifs afin de faire de l’analyse orientée “business” grâce à Logstash, ElasticSearch et Kibana.
Dans ce billet de blog, nous serons à la tête d’un site fictif de vente en ligne, et essaierons de répondre aux questions suivantes :
- Quel est le ratio recherches / ventes ?
- Quels sont les critères de recherches les plus utilisés ?
- Quels sont les produits les plus consultés ?
- Quels sont les produits les plus vendus (iPhone 5S, Galaxy S4) ?
- Quels sont les modèles les plus vendus (iPod Shuffle Bleu, iPhone 5S 64 Go Argent) ?
- Qui sont mes plus fidèles clients ? Où sont-ils (géo)localisés ?
- Quelle est la proportion homme / femme de mes acheteurs ?
- Où nous situons-nous par rapport à nos objectifs de ventes ?
- etc…
Format des logs
Ce paragraphe vous présente le format des logs que nous allons exploiter.
Vous pouvez utiliser l’application log-generator disponible sur Github afin de générer des logs facilement.
Voici un exemple permettant de générer 10 logs, puis 100 logs toutes les secondes sur 2 threads :
git clone https://github.com/vspiewak/log-generator.gitcd log-generatormvn clean packagejava -jar target/log-generator-0.0.1-SNAPSHOT.jar -n 10java -jar target/log-generator-0.0.1-SNAPSHOT.jar -n 100 -r 1000 -t 2Voici quelques exemples de recherches/visites d’un produit :
08-10-2013 16:33:46.585 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=1,ip=92.90.16.222,category=Portable08-10-2013 16:33:47.627 [pool-1-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=12,ip=90.33.93.13,category=Mobile,brand=Samsung08-10-2013 16:33:49.628 [pool-1-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=35,ip=82.121.185.168,category=Portable,brand=Apple,options=Ecran 11|Disque 128Go08-10-2013 16:33:49.629 [pool-1-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=41,ip=157.55.34.94,brand=Dans l’exemple ci-dessus, les logs représentent respectivement :
- une requête (id 1) de recherche sur la catégorie “Portable”, venant de l’ip 92.90.16.222
- une requête (id 12) de recherche sur la catégorie “Mobile” et la marque “Samsung”, venant de l’ip 90.33.93.13
- une requête (id 35) de recherche sur la catégorie “Portable” et la marque “Apple”, avec un écran 11 pouces et un disque 128 Go, venant de l’ip 82.121.185.168
- une visite (id 41) du produit “iPhone 5C”, modèle blanc avec une capacité de 16Go, au prix de 599 €, venant de l’ip 157.55.34.94
Voici un exemple de log d’une vente :
08-10-2013 16:33:50.586 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SellRequest - id=53,ip=193.248.203.28,email=client16@gmail.com,sex=F,brand=Google,name=Nexus 10,model=Nexus 10 - Disque 16Go,category=Tablette,options=Disque 16Go,price=399.0Ici, le log nous informe que notre cliente a acheté une Tablette Nexus 10 de capacité 16Go au prix de 399€.
Logstash
Logstash est un pipe permettant de collecter, parser, et stocker des logs à l’aide d’entrées, de filtres et de sorties (input, filter, output).
La phase de parsing permet d’ajouter de la sémantique à notre événement, en ajoutant, modifiant ou supprimant des champs, des tags, des types, etc…
Cet article utilise la version 1.2.1 de Logstash, qui comporte entre autres :
- 37 types d’entrée
- 39 filtres
- 51 types de sortie
De quoi vous brancher à pas mal de systèmes au sein de votre SI…
Le JAR est disponible à cette adresse : https://download.elasticsearch.org/logstash/logstash/logstash-1.2.1-flatjar.jar
Configuration minimale
Créez un fichier de configuration minimaliste nommé “logstash-logback.conf” :
input { stdin {}}
output { stdout { debug => true }}Lancez Logstash avec cette configuration :
java -jar logstash-1.2.1-flatjar.jar agent -f logstash-logback.confCopiez/collez dans l’entrée standard une ligne de log :
02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRTLogstash affichera alors sa représentation au moment de la réception :
{ "message" => "02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRT", "@timestamp" => "2013-10-02T14:08:52.356Z", "@version" => "1", "host" => "D-CZC1444LWN-LX"}Le champ message contient la ligne de log brute, @timestamp contient la date de l’événement.
Un œil averti aura remarqué que le champ @timestamp n’est pas le même que la ligne originale.
Logstash a en effet pris la date d’insertion ne sachant pas quel “bout” de log utiliser.
Le premier travail va consister à parser le log à l’aide d’une regex…
Ajout de sémantique avec le filtre Grok
Le filtre grok va nous permettre de parser les lignes de logs et leur donner de la sémantique.
Logstash vient avec plus d’une centaine d’expressions régulières prédéfinies (disponibles ici : https://github.com/logstash/logstash/tree/master/patterns).
Par exemple, le pattern “COMBINEDAPACHELOG” du fichier grok-patterns permet de matcher les lignes de logs d’un serveur Apache.
Vous pouvez utiliser 2 syntaxes :
%{SYNTAX:SEMANTIC} ou%{SYNTAX:SEMANTIC:TYPE}(?<field_name>the pattern here)
La première syntaxe réutilise un pattern Logstash (ex: MONTHDAY, NOTSPACE, LOGLEVEL, …), SEMANTIC étant le nom du champ à mapper.
Vous pouvez aussi préciser le type du champ (integer, float, String) via le paramètre TYPE.
La deuxième syntaxe vous permet de définir un pattern customisé avec ou sans l’aide de plusieurs patterns “logstash”.
Voici une configuration permettant de parser nos logs :
input { stdin {}}
filter { grok { match => ["message","(?<log_date>%{MONTHDAY}-%{MONTHNUM}-%{YEAR} %{HOUR}:%{MINUTE}:%{SECOND}.[0-9]{3}) \[%{NOTSPACE:thread}\] %{LOGLEVEL:log_level} %{NOTSPACE:classname} - %{GREEDYDATA:msg}"] }}
output { stdout { debug => true }}Si vous relancez Logstash, et copiez/collez la première ligne, vous devriez obtenir une sortie similaire :
02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRT
{ "message" => "02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRT", "@timestamp" => "2013-10-02T14:13:50.357Z", "@version" => "1", "host" => "D-CZC1444LWN-LX", "log_date" => "02-10-2013 14:26:27.724", "thread" => "pool-10-thread-1", "log_level" => "INFO", "classname" => "com.github.vspiewak.loggenerator.SearchRequest", "msg" => "id=9205,ip=217.109.49.180,cat=TSHIRT"}On remarque que Logstash a parsé les champs log_date, thread, log_level, classname et msg.
Lorsque Grok échoue, il ajoute le tag “_grokparsefailure” à votre évènement :
This line will fail obviously...
{ "message" => "This line will fail obviously...", "@timestamp" => "2013-10-02T13:36:53.290Z", "@version" => "1", "host" => "D-CZC1444LWN-LX", "tags" => [ [0] "_grokparsefailure" ]}Dossier de patterns
Plutôt que d’utiliser une longue expression régulière dans votre configuration, définissez un fichier contenant vos patterns personnalisés.
Créez un dossier “patterns” dans votre répertoire courant.
Créez un fichier “logback” dans le dossier “patterns” contenant :
LOG_DATE %{MONTHDAY}-%{MONTHNUM}-%{YEAR} %{HOUR}:%{MINUTE}:%{SECOND}.[0-9]{3}#LOGBACK_LOG %{LOG_DATE:log_date} [%{NOTSPACE:thread}] %{LOGLEVEL:log_level} %{NOTSPACE:classname} - %{GREEDYDATA:msg}Indiquez ensuite à Grok le dossier contenant vos fichiers de patterns via l’attribut “patterns_dir”.
La configuration Losgstash devient :
input { stdin {}}
filter { grok { patterns_dir => "./patterns" match => [ "message", "%{LOG_DATE:log_date} \[%{NOTSPACE:thread}\] %{LOGLEVEL:log_level} %{NOTSPACE:classname} - %{GREEDYDATA:msg}"] }}
output { stdout { debug => true }}Le bon @Timestamp avec le filtre date
Le filtre date est l’un des filtre les plus importants. Il permet en effet de parser une date et de l’utiliser pour le champ @timestamp.
Cette étape est cruciale (souvenez-vous du panel “timepicker” dans Kibana…).
Vous pouvez spécifier les 4 formats de date suivants :
- “ISO8601” : timestamp ISO8601 (ex: 2011-04-19T03:44:01.103Z)
- “UNIX” : temps écoulé depuis epoch en secondes
- “UNIX_MS” : temps écoulé depuis epoch en millisecondes
- “TAI64N”
- un pattern au format org.joda.time.format.DateTimeFormat
Dans notre configuration, nous allons utiliser un pattern au format Joda :
input { stdin {}}
filter { grok { patterns_dir => "./patterns" match => [ "message", "%{LOG_DATE:log_date} \[%{NOTSPACE:thread}\] %{LOGLEVEL:log_level} %{NOTSPACE:classname} - %{GREEDYDATA:msg}"] }}
filter { date { match => ["log_date","dd-MM-YYYY HH:mm:ss.SSS"] }}
output { stdout { debug => true }}Le champ @timestamp utilise enfin la date de notre log :
02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRT
{ "@timestamp" => "2013-10-02T12:26:27.724Z", "@version" => "1", "classname" => "com.github.vspiewak.loggenerator.SearchRequest", "datas" => "id=9205,ip=217.109.49.180,cat=TSHIRT", "host" => "0:0:0:0:0:0:0:1:55773", "log_level" => "INFO", "logdate" => "02-10-2013 14:26:27.724", "message" => "02-10-2013 14:26:27.724 [pool-10-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=9205,ip=217.109.49.180,cat=TSHIRT", "thread" => "pool-10-thread-1", "type" => "ibay"}Vous pouvez le vérifier en copiant/collant plusieurs fois la même ligne de log, Logstash devrait utiliser le même timestamp.
Parsing d’un champ avec le filtre kv
Le filtre kv s’avère très utile lorsque vous voulez parser un champ de type foo=bar comme par exemple une requête HTTP.
Ajoutez le filtre kv pour notre example :
filter { kv { field_split => "," source => "msg" }}Logstash parse maintenant notre ligne de vente et ajoute automatiquement les champs category, brand, name, model, color, options et price :
{ "@timestamp" => "2013-10-08T14:33:49.629Z", "@version" => "1", "brand" => "Apple", "category" => "Mobile", "classname" => "com.github.vspiewak.loggenerator.SearchRequest", "color" => "Blanc", "host" => "0:0:0:0:0:0:0:1:60860", "id" => "41", "ip" => "157.55.34.94", "log_level" => "INFO", "logdate" => "08-10-2013 16:33:49.629", "message" => "08-10-2013 16:33:49.629 [pool-1-thread-1] INFO com.github.vspiewak.loggenerator.SearchRequest - id=41,ip=157.55.34.94,brand=Apple,name=iPhone 5C,model=iPhone 5C - Blanc - Disque 16Go,category=Mobile,color=Blanc,options=Disque 16Go,price=599.0", "model" => "iPhone 5C - Blanc - Disque 16Go", "msg" => "id=41,ip=157.55.34.94,brand=Apple,name=iPhone 5C,model=iPhone 5C - Blanc - Disque 16Go,category=Mobile,color=Blanc,options=Disque 16Go,price=599.0", "name" => "iPhone 5C", "options" => "Disque 16Go", "price" => "599.0", "thread" => "pool-1-thread-1", "type" => "ibay"}Conditions
Logstash permet d’utiliser des conditions via la syntaxe :
if EXPRESSION { ...} else if EXPRESSION { ...} else { ...}Les expressions peuvent contenir :
- une égalité, comparaison :
== != < > <= >= - un pattern :
=~ !~ - une inclusion :
in not in - un opérateur booléen :
and, or, nand, xor - un opérateur unaire :
!
Filtre mutate
Ajout d’un tag
Le filtre mutate est un filtre “couteaux suisses” permettant une multitude de modifications.
Nous allons ajouter un tag à nos logs afin de différencier les recherches des ventes :
filter { if [classname] =~ /SellRequest/ { mutate { add_tag => "sell" } } else if [classname] =~ /SearchRequest$/ { mutate { add_tag => "search" } }}Conversion de type
Le filtre mutate permet de convertir certains champs en entier, flottant ou string.
Nous ajoutons à notre configuration la conversion des champs id et price :
filter { mutate { convert => [ "id", "integer" ] } mutate { convert => [ "price", "float" ] }}Suppression d’un champ
Toujours avec le filtre mutate, nous allons supprimer le champ “msg”.
Nous avons en effet parsé ce champ avec le filtre kv et n’avons plus besoin de ce doublon d’information.
Ajoutez à la suite du dernier bloc de filtre :
filter { mutate { remove_field => [ "msg" ] }}Split d’un champ
Pour finir avec le filtre mutate, nous allons splitté notre champ “options” afin d’avoir un tableau d’options.
filter { mutate { split => [ "options", "|" ] }}Au final, l’utilisation du filtre mutate nous a permis d’obtenir la sortie suivante :
08-10-2013 16:33:48.586 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SellRequest - id=16,ip=78.250.209.114,email=client17@gmail.com,sex=M,brand=Apple,name=Macbook Air,model=Macbook Air - Ecran 13 - Disque 128Go,category=Portable,options=Ecran 13|Disque 128Go,price=1099.0
{ "@timestamp" => "2013-10-08T14:33:48.586Z", "@version" => "1", "brand" => "Apple", "category" => "Portable", "classname" => "com.github.vspiewak.loggenerator.SellRequest", "email" => "client17@gmail.com", "host" => "macbookpro", "id" => 16, "ip" => "78.250.209.114", "log_date" => "08-10-2013 16:33:48.586", "log_level" => "INFO", "message" => "08-10-2013 16:33:48.586 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SellRequest - id=16,ip=78.250.209.114,email=client17@gmail.com,sex=M,brand=Apple,name=Macbook Air,model=Macbook Air - Ecran 13 - Disque 128Go,category=Portable,options=Ecran 13|Disque 128Go,price=1099.0", "model" => "Macbook Air - Ecran 13 - Disque 128Go", "name" => "Macbook Air", "options" => [ [0] "Ecran 13", [1] "Disque 128Go" ], "price" => 1099.0, "sex" => "M", "tags" => [ [0] "sell" ], "thread" => "pool-2-thread-1"}GeoIP
Le filtre geoip permet d’ajouter des informations de géolocalisation via une adresse ip (ou hostname).
Logstash utilise la base de donnée GeoLite de Maxmind sous license CCA-ShareAlike 3.0.
Ici j’utilise une version de GeoLite City (format Binary / GZip) téléchargée au préalable sur le site Maxmind plutôt que la version embarquée dans Logstash :
filter { geoip { source => "ip" database => "./GeoLiteCity.dat" }}Logstash ajoute un champ geoip contenant les précieuses informations de géolocalisations :
"geoip" => { "ip" => "217.***.***.180", "country_code2" => "FR", "country_code3" => "FRA", "country_name" => "France", "continent_code" => "EU", "region_name" => "A8", "city_name" => "Paris", "postal_code" => "", "latitude" => 48.86670000000001, "longitude" => 2.3333000000000084, "dma_code" => nil, "area_code" => nil, "timezone" => "Europe/Paris", "real_region_name" => "Ile-de-France"}GeoIP et Bettermap
Le panel Bettermap de Kibana requiert un champ contenant les coordonnées GPS au format Geo_JSON (format : [ longitude, latitude ]).
Nous allons ajouter un champ “geoip.lnglat” contenant le tableau de coordonnées via le “hack” suivant :
filter {
# 'geoip.lnglat' will be kept, 'tmplat' is temporary. # Both of these new fields are strings. mutate { add_field => [ "[geoip][lnglat]", "%{[geoip][longitude]}", "tmplat", "%{[geoip][latitude]}" ] }
# Merge 'tmplat' into 'geoip.lnglat' mutate { merge => [ "[geoip][lnglat]", "tmplat" ] }
# Convert our new array of strings back to float # Delete our temporary latitude field mutate { convert => [ "[geoip][lnglat]", "float" ] remove => [ "tmplat" ] }
}Configuration Logstash finale
Pour rappel, voici le contenu final du fichier de configuration de Logstash :
input { stdin {} file { path => "/tmp/logstash/*.log" }}
filter { grok { patterns_dir => "./patterns" match => ["message","%{LOG_DATE:log_date} \[%{NOTSPACE:thread}\] %{LOGLEVEL:log_level} %{NOTSPACE:classname} - %{GREEDYDATA:msg}"] }}
filter { date { match => ["log_date","dd-MM-YYYY HH:mm:ss.SSS"] }}
filter { kv { field_split => "," source => "msg" }}
filter { if [classname] =~ /SellRequest$/ { mutate { add_tag => "sell" } } else if [classname] =~ /SearchRequest$/ { mutate { add_tag => "search" } }}
filter { mutate { remove_field => [ "msg" ] }}
filter { mutate { convert => [ "id", "integer" ] } mutate { convert => [ "price", "float" ] }}
filter { mutate { split => [ "options", "|" ] }}
filter { geoip { source => "ip" database => "./GeoLiteCity.dat" }}
filter { mutate { add_field => [ "[geoip][lnglat]", "%{[geoip][longitude]}", "tmplat", "%{[geoip][latitude]}" ] } mutate { merge => [ "[geoip][lnglat]", "tmplat" ] } mutate { convert => [ "[geoip][lnglat]", "float" ] remove_field => [ "tmplat" ] }}
output { stdout { debug => true } elasticsearch { }}
08-10-2013 16:33:48.586 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SellRequest - id=16,ip=78.250.209.114,email=client17@gmail.com,sex=M,brand=Apple,name=Macbook Air,model=Macbook Air - Ecran 13 - Disque 128Go,category=Portable,options=Ecran 13|Disque 128Go,price=1099.0
{ "@timestamp" => "2013-10-08T14:33:48.586Z", "@version" => "1", "brand" => "Apple", "category" => "Portable", "classname" => "com.github.vspiewak.loggenerator.SellRequest", "email" => "client17@gmail.com", "geoip" => { "area_code" => nil, "city_name" => "Paris", "continent_code" => "EU", "country_code2" => "FR", "country_code3" => "FRA", "country_name" => "France", "dma_code" => nil, "ip" => "78.250.209.114", "latitude" => 48.86670000000001, "lnglat" => [ [0] 2.3333000000000084, [1] 48.86670000000001 ], "longitude" => 2.3333000000000084, "postal_code" => "", "real_region_name" => "Ile-de-France", "region_name" => "A8", "timezone" => "Europe/Paris" }, "host" => "macbookpro", "id" => 16, "ip" => "78.250.209.114", "log_date" => "08-10-2013 16:33:48.586", "log_level" => "INFO", "message" => "08-10-2013 16:33:48.586 [pool-2-thread-1] INFO com.github.vspiewak.loggenerator.SellRequest - id=16,ip=78.250.209.114,email=client17@gmail.com,sex=M,brand=Apple,name=Macbook Air,model=Macbook Air - Ecran 13 - Disque 128Go,category=Portable,options=Ecran 13|Disque 128Go,price=1099.0", "model" => "Macbook Air - Ecran 13 - Disque 128Go", "name" => "Macbook Air", "options" => [ [0] "Ecran 13", [1] "Disque 128Go" ], "price" => 1099.0, "sex" => "M", "tags" => [ [0] "sell" ], "thread" => "pool-2-thread-1"}La configuration finale de logstash parsera tous les logs générés dans le dossier /tmp/logstash. Vous pouvez lancer la génération de logs via la commande :
java -jar target/log-generator-0.0.1-SNAPSHOT.jar -n 10 -r 1000 -t 2 > /tmp/logstash/app.logElasticsearch
Nous allons installer Elasticsearch ainsi que le plugin head afin de stocker nos logs. Nous utiliserons ici la version 0.90.3, comme recommandé dans la documentation Logstash (pour les sorties elasticsearch & elasticsearch_http):
curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.90.3.zipunzip elasticsearch-0.90.3.zipcd elasticsearch-0.90.3/
bin/plugin --install mobz/elasticsearch-headIl ne nous reste plus qu’à lancer Elasticsearch :
./bin/elasticsearch -f[2013-11-24 20:22:49,444][INFO ][node ] [Red Skull II] version[0.90.3], pid[4986], build[5c38d60/2013-08-06T13:18:31Z][2013-11-24 20:22:49,445][INFO ][node ] [Red Skull II] initializing ...[2013-11-24 20:22:49,450][INFO ][plugins ] [Red Skull II] loaded [], sites [][2013-11-24 20:22:51,356][INFO ][node ] [Red Skull II] initialized[2013-11-24 20:22:51,357][INFO ][node ] [Red Skull II] starting ...[2013-11-24 20:22:51,448][INFO ][transport ] [Red Skull II] bound_address {inet[/0:0:0:0:0:0:0:0:9300]}, publish_address {inet[/192.168.1.5:9300]}[2013-11-24 20:22:54,478][INFO ][cluster.service ] [Red Skull II] new_master [Red Skull II][SBR_oXvoTySk0ubW8zX2ow][inet[/192.168.1.5:9300]], reason: zen-disco-join (elected_as_master)[2013-11-24 20:22:54,498][INFO ][discovery ] [Red Skull II] elasticsearch/SBR_oXvoTySk0ubW8zX2ow[2013-11-24 20:22:54,508][INFO ][http ] [Red Skull II] bound_address {inet[/0:0:0:0:0:0:0:0:9200]}, publish_address {inet[/192.168.1.5:9200]}[2013-11-24 20:22:54,508][INFO ][node ] [Red Skull II] started[2013-11-24 20:22:54,522][INFO ][gateway ] [Red Skull II] recovered [0] indices into cluster_stateVous pouvez visualiser votre cluster Elasticsearch via le plugin head à l’adresse : http://localhost:9200/_plugin/head
Par défaut, Logstash enverra vos logs dans des indices Elasticsearch nommés “logstash-YYYY-MM-DD”.
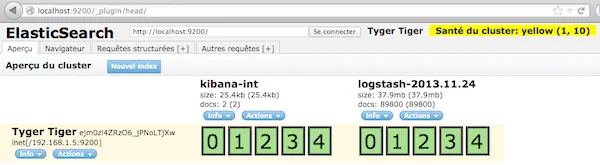
Template de mapping Elasticsearch
Elasticsearch ne nécessite aucune configuration particulière pour fonctionner avec Logstash. Cependant, pour cet exemple, nous allons désactiver l’analyseur utilisé sur certains champs. Cela s’avère utile pour notre dashboard Kibana qui utilise notamment des panels de type “terms”.
curl -XPUT http://localhost:9200/_template/logstash_per_index -d '{ "template" : "logstash*",
"mappings" : { "_default_" : { "_all" : {"enabled" : false}, "properties" : { "@timestamp": { "type": "date", "index": "not_analyzed" }, "ip": { "type" : "ip", "index": "not_analyzed" }, "name": { "type" : "string", "index": "not_analyzed" }, "model": { "type" : "string", "index": "not_analyzed" }, "options": { "type" : "string", "index": "not_analyzed" }, "email": { "type" : "string", "index": "not_analyzed" }
} } }}'Cette requête désactive l’analyseur pour les champs “ip”, “name”, “model”, “options” et “email”. Cela vous évitera des écueils lors de l’affichage des “top clients” ou “top produits”:
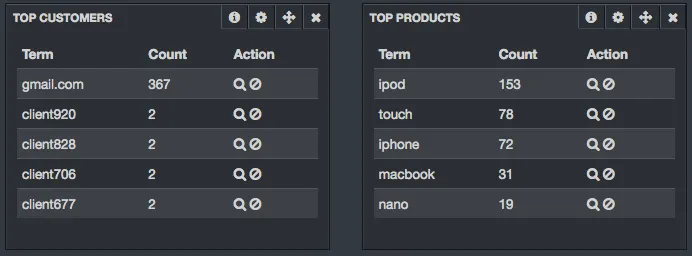
Kibana
Pour installer Kibana, il vous faut également un serveur web. L’exemple est donné pour une installation standard d’Apache, mais tout autre serveur web capable de servir des fichiers statiques fera l’affaire.
curl -O https://download.elasticsearch.org/kibana/kibana/kibana-3.0.0milestone4.zipunzip kibana-3.0.0milestone4.zipsudo mv kibana-3.0.0milestone4 /var/www/kibanaVous pouvez désormais accéder à Kibana à l’adresse : http://localhost/kibana
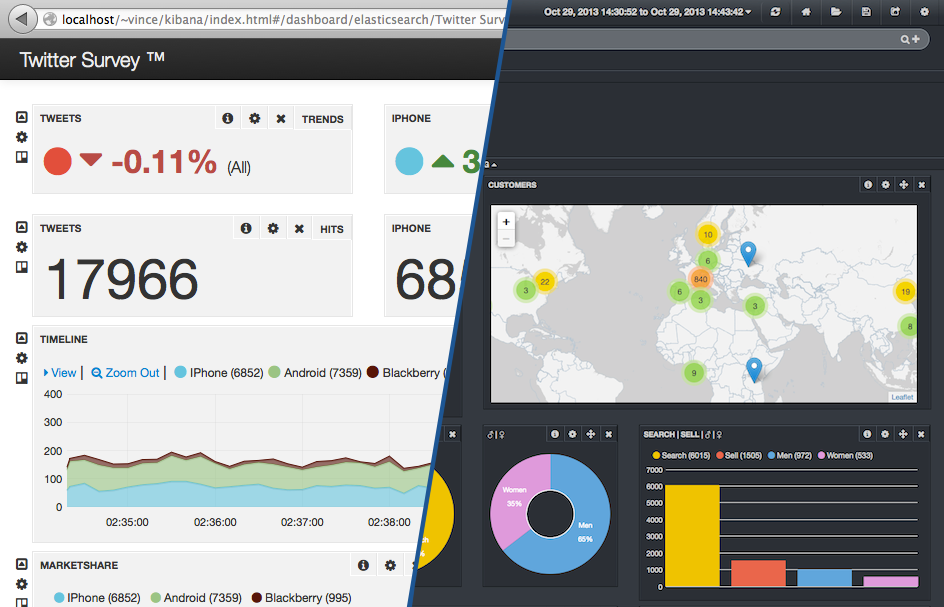
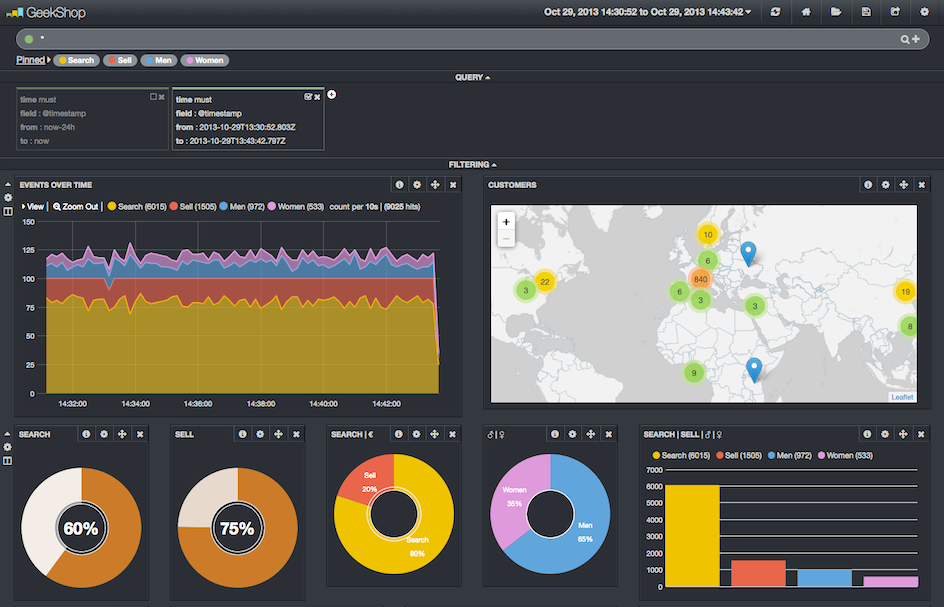
Un dashboard pré-configuré est disponible en téléchargement ici : dashboard.json
Il ne vous reste plus qu’à charger le dashboard via le menu Load > Advanced > Local File.
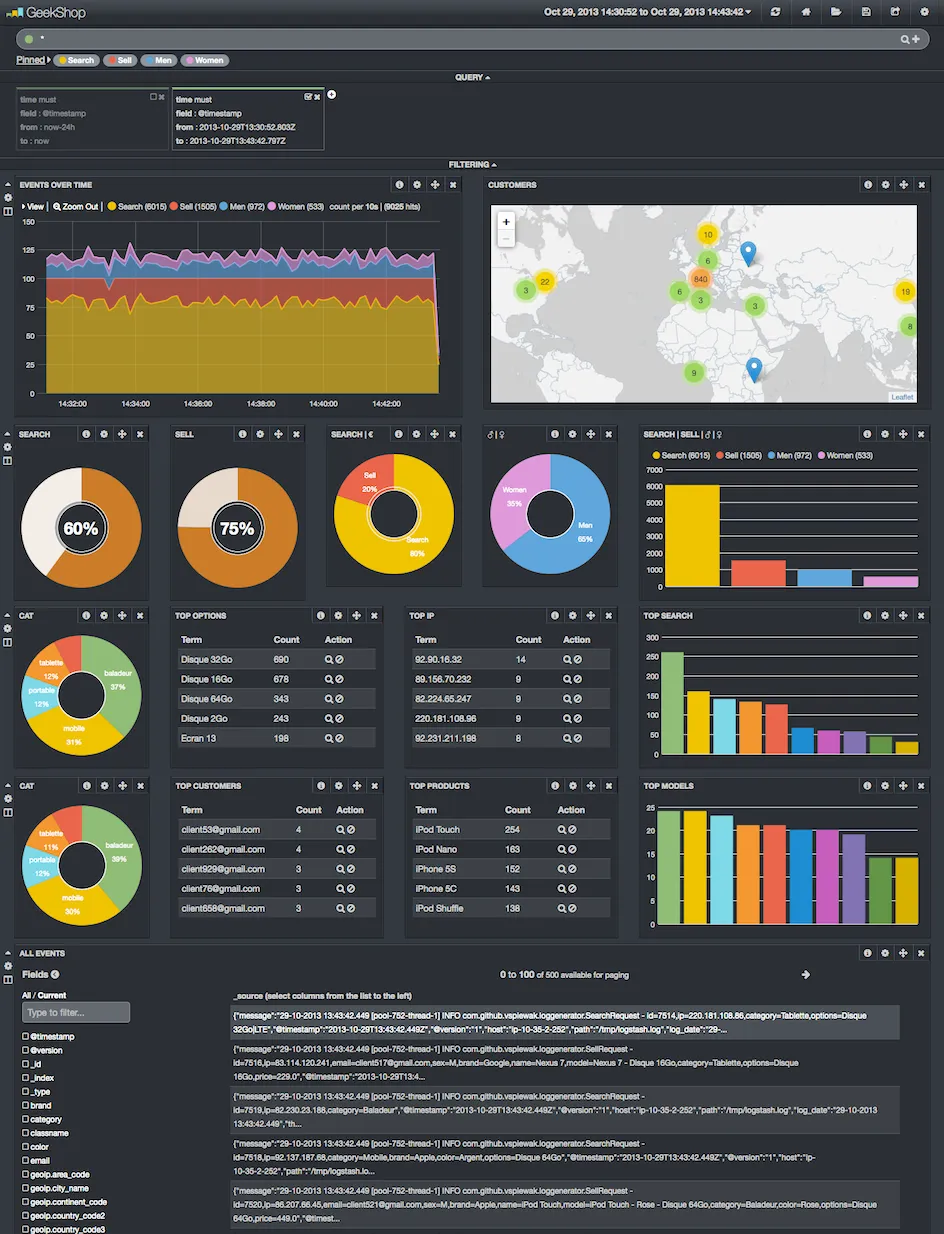
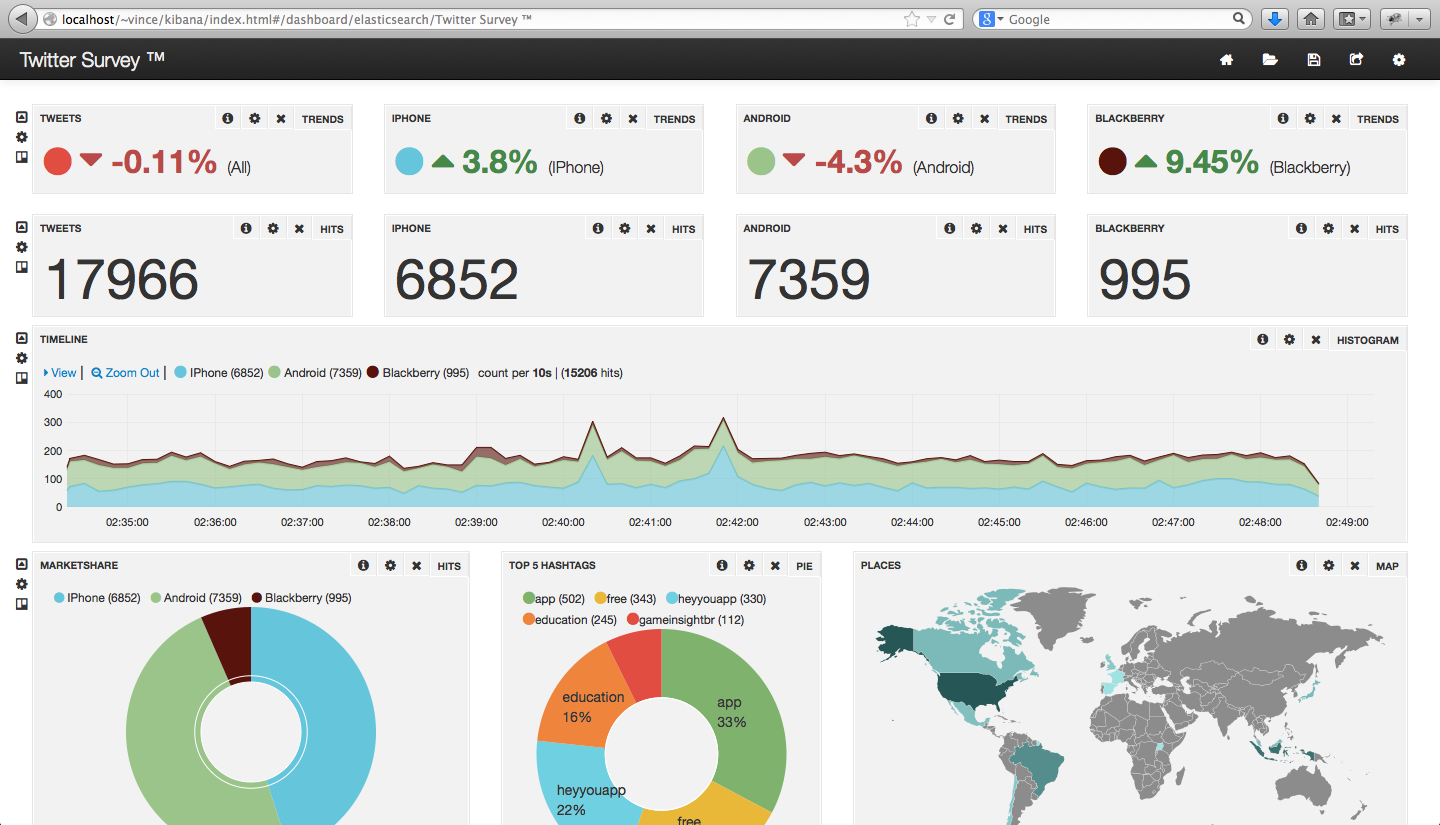
Sur cette capture d’écran, nous remarquons notamment que :
- Il y a 20% de ventes, et 80% de recherches
- 35% des clients sont des femmes
- 39% des produits vendus sont des baladeurs
- 254 iPod Touch ont été vendus pour la période de temps sélectionnée
- 3 requêtes (recherche ou vente) viennent des Etats-Unis
Pour aller plus loin
Des filtres peuvent être créés dynamiquement en cliquant sur les différents éléments du dashboard (notamment les petites loupes). Ils apparaissent dans le panel filtering sous forme de boîtes. En quelques clics, vous pouvez restreindre les résultats de vos queries sur un modèle, une option particulière, ou tout autre champ disponible. Vous aurez notamment la possibilité de suivre l’évolution des achats de téléphone Nexus 4 (modèle 16 Go, couleur Blanc) effectués par des femmes habitant sur Paris pour la période du 15 novembre au 25 décembre.
Sources
- http://bryanw.tk/2013/geoip-in-logstash-kibana
- http://elasticsearch-users.115913.n3.nabble.com/need-count-of-terms-using-facets-taking-space-into-account-td3956699.html
- https://gist.github.com/deverton/2970285
- http://untergeek.com/2012/09/20/using-templates-to-improve-elasticsearch-caching-with-logstash/